Continuiamo a parlare del livello di rete, affrontando nel dettaglio l’ argomento di Routing dei pacchetti.
[note_box]Il routing stabilisce quale percorso deve seguire un pacchetto per raggiungere la sua destinazione.[/note_box]
In Internet esistono migliaia di router: quale strada dovrebbe fare un pacchetto per arrivare da un punto A a un punto B? Il routing è proprio ciò che si occupa di trovare il miglior percorso (o route/path) e inserirlo nella tabella di routing (o forwarding). Ricordiamo ciò che abbiamo detto qualche articolo fà: il routing costruisce le tabelle mentre è il forwardin ad usarle!
Per rappresentare una rete, utilizzeremo un grafo:
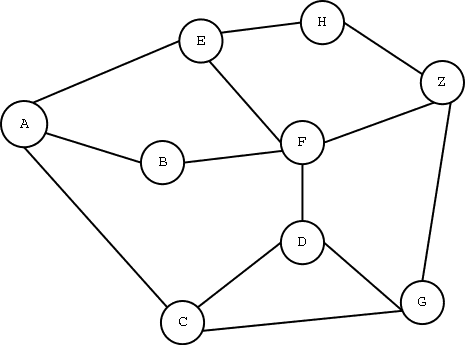
Ogni collegamento, ad esempio fra A e C, ha un costo. Il compito dell’ algoritmo di instradamento è quello di determinare il cammino a costo minimo.
[info_box]
Il costo di un cammino è la somma di tutti i costi degli archi lungo il cammino.
[/info_box]
Classificazione degli algoritmi di instradamento
Gli algoritmi di routing possono essere suddivisi in:
- Globale: L’ algoritmo riceve in ingresso tutti collegamenti tra i nodi e i loro costi. Algoritmi a stato del collegamento (link-state alogirhtm).
- Decentralizzato: Ogni nodo elabora un vettore di stime dei costi (distanze) verso tutti gli altri nodi della rete ed il cammino a costo minimo viene calcolato in modo distribuito e iterativo. Algoritmo a vettore distanza (VC, distance-vector algorithms).
Possono essere inoltre suddivisi in:
- Statico: I cammini cambiano molto raramente.
- Dinamico: Determinano gli instradamenti al variare di Volume di traffico e Topologia della rete.
Le differenze tra gli algoritmi consistono nel modo che essi interpretano il costo minimo e creano l’ albero a costo minimo per ciascun nodo. Più avanti vedremo come questi algoritmi ( non protocolli) vendono implementato in protocolli di routing.
Cominciamo quindi a vedere gli algoritmi di routing a stato del collegamneto (LS):
Algoritmo d’instradamento a stato del collegamento (LS)
La topologia di rete e tutti i costi del collegamenti sono noti a tutti i nodi attraverso i link-state broadcast tutti i nodi dispongono delle stesse informazioni
Calcola il cammino a costo minimo da un nodo(origine) a tutti gli altri nodi della rete e crea una tabella di inoltro.
E’ iterativo, ovvero dopo la k-esima iterazione i cammini a costo minimo sono noti a k nodi di destinazione.
Prima di continuare diamo un pò di notazione:
- c(x,y): costo del collegamenti dal nodo x al nodo y
- D(v): costo del cammino minimo dal nodo origine alla destinazione v per quanto riguarda l’ iterazione corrente.
- p(v): immediato predecessore di v lungo il cammino.
- N’: sottoinsieme di nodi per cui il cammino a costo minimo dall’ origine è definitivamente noto.
L’ algoritmo di Dijsktra calcola i percorsi di costo minimo da un nodo u a tutti gli altri nodi della rete. E’ iterativo e viene eseguito un numero di volte pari al numero di nodi della rete:
N' = {u} /* u è il nodo che esegue l' algoritmo (radice dell' albero)*/
per tutti i nodi v
se v è adiacente a u
allora D(v) = c(u,v)
altrimenti D(v) = infinito
-Ciclo
determina un w non in N' tale che D(w) sia minimo
aggiungi w a N'
per ogni nodo v adiacente a w e non in N' aggiorna D(v):
D(v)= min(D(v),D(w) + c(w,v))
/* il nuovo costo verso v è il vecchio costo verso v oppure
il costo del cammino minimo noto vero w più il costo da w a v */
Finchè N' = N torna a -Ciclo
Vediamo di analizzarlo riga per riga:
- Crea N’ e ci inserisce il nodo che vuole scoprire i cammini minimi per ogni nodo della rete (ovvero il nodo che ha avviato l’algoritmo). Infatti il cammino minimo verso se stesso è ovviamente noto.
- Per tutti i nodi adiacenti (righe 2 e 3), se sono adiacenti il cammino a costo minimo è dato per forza dal collegamento fra il nodo u e loro e perciò li inseriamo in quanto il cammino minimo è noto.
- Dopodichè, entra in un ciclo che prende un nodo w di cui non si conosce il cammino minimo e lo calcola.
- Una volta calcolato, aggiunge w a N’ e per ogni nodo v adiacente a w e non presente fra i nodi di cui si conosce il cammino minimo (N’) aggiorna D(v) eseguendo la formula:
- D(v) = min(D(v), D(w)+c(w,v))
- Che altro non fà che dire: Se il cammino minimo del nodo v lo riesco a trovare in maniera diretta prendi quello, ma se preso il cammino per nodo w (adiacente a v) e sommatoci il costo per andare da w a v è minore di questo, allora scegli questo come cammino.
Algortimo d’ instradamento con vettore distanza (Distance Vector- DV)
E’ un tipo di algoritmo Distribuito, ovvero ogni nodo riceve informazione dai vicini e opera su quelle; ed Asincrono, cioè non richiede che tutti i nodi operino al passo con gli altri.
Si basa su:
- Equazione di Bellman–Ford,
- Concetto di vettore distanza.
Equazione di Bellman-Ford
Dx(y) = Il costo (o la distanza) del percorso a costo minimo dal nodo x al nodo y
Allora:
Dx(y) = minv{c(x,v) + Dv(y)}
Dove minv riguarda tutti i vicini di x.
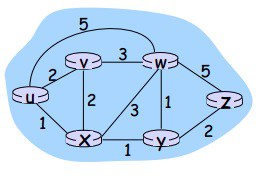
Ad esempio: La formula B-F definisce du(z) come:
du(z) = min{ c(u,v) + dv(z), c(u,x) + dx(z), c(u,w) + dw(z)}
= min{2+5, 1+3, 5+3} = 4
Vettore distanza
Un albero a costo minimo è una combinazione di percorsi a costo minimo dalla radice dell’ albero verso tutte le destinazioni. Il vettore a distanza, altro non è che un array monodimensionale che rappresenta un albero.
Un vettore distanza non fornisce però il percorso da seguire per giungere alla destinazione, ma solo i costi minimi per le destinazioni.
Per creare un vettore distanza ogni nodo della rete quando viene inizializzato crea un vettore distanza iniziale con le proprie informazioni che il nodo riesce a ottenere dai propri vicini (nodi con cui è direttamente collegato).
Per creare il vettore dei vicini invia messaggi di hello attraverso le sue interfacce( e lo stesso fanno i vicini e scopre l’ identità dei vicini e la sua distanza da ognuno di essi.
Il vettore iniziale rappresenta il vettore a costo minimo verso i vicini. Dopo che ogni nodo ha creato il suo vettore ne invia una copia ai suoi vicini e quando ogni nodo riceve un vettore distanza da un vicino provvede ad aggiornare il suo vettore distanza applicando l’ equazione di Bellman-Ford vista poco fà.
Algoritmo con vettore distanza
L’ idea di base dietro questo tip di algoritmo, è che ogni nodo invia una copia del proprio vettore distanza a ciascuno dei suoi vicini. Quando un nodo x riceve un vettore distanza, DV, da qualcuno dei suoi vicini, lo salva e usa la formula B-F per assegnare al proprio vettore distanza come segue:
Dx(y) = minv {c(x,v)+Dv(y)} per ciascun nodo y in N
Se il vettore distanza del nodo x è cambiato per via di tale passo di aggiornamento, il nodo x manderà il proprio vettore distanza aggiornato a ciascuno dei suoi vicini, i quali a loro volta aggiornano il loro vettore distanza.
E’ asincrono e iterativo come già abbiamo detto perchè ogni iterazione locale è causata da un cambio del costo di uno dei collegamenti locali o dalla ricezione da qualche vicino di un vettore distanza aggiornato; ed è Distribuito perchè ogni nodo aggiorna i suoi vicini solo quando il suo DV cambia (e vicini faranno lo stesso solo se necessario)
Inizializzazione
per tutte le destinazioni y in N:
Dx(y) = c(x,y) //c(x,y)=∞ se y non vicino
per ciascun vicino w
Dw(y) = ∞ per tutte le destinazioni y in N
per ciascun vicino w
invia il vettore distanza Dx = [Dx(y): y in N] a w
Ciclo
attendi (finchè vedi cambiare il costo di un collegamento
verso qualche vicino w o ricevi un vettore distanza
da qualche vicino w)
per ogni y in N:
Dx(y) = minv {c(x,y) + Dv(y)}
se qualche Dx(y) è cambiato invia vettore distanza Dx a
tutti i vicini
Confronto fra LS e DV
Vediamo di confrontare questi due tipi di algoritmi.
Complessità dei messaggi:
- LS: con n nodi, E collegamenti, implica l’ invio di O(n*E) messaggi (ogni nodo deve conoscere il costo degli E link).
- DV: richiede scambi tra nodi adiacenti. Il tempo di convergenza può variare
Velocità di convergenza:
- LS: L’algoritmo ha complessita O(n2) procede prima n nodi, poi n-1, n-2 quindi (n(n+1)/2)
- DV: può convergere lentamente. Può presentare cicli d’ instradamento e può presentare il problema del conteggio all’ infinito.
Robustezza (cosa avviene se un router ad esempio funzioni male):
- LS: Un router può comunicare via broadcast un costo sbagliato per uno dei suoi collegamenti connessi (ma non per altri). I nodi si occupano di calcolare soltanto le proprie tabelle.
- DV: Un nodo può comunicare cammini a costo minimo errati a tutte le destinazioni. La tabella di ciascun nodo può essere usata dagli altri (un calcolo errato quindi si può diffondere per l’intera rete).
Algoritmo Path Vector
E’ simile al distance vector, solo che invece che solo le destinazioni vengono invuati i percorsi. Ogni nodo che riceve un Path Vector applica la sua politica invece del costo minimo.
Protocolli di Routing
Come già abbiamo detto, una rete può essere vista come un grafo su cui lavoriamo usando gli algoritmi, ma quello che applichiamo sono Protocolli di Routing (che sfruttano idee degli algoritmi di routing).
I rispettivi protocolli basati sugli algoritmi di routing che abbiamo visto sono:
- Routing Information Protocol (RIP): Basato sull’algoritmo Distance Vector,
- Open Shortest Path First (OSPF): Basato su Link State,
- Border Gateway Protocol (BGP): Basato su Path Vector.
In internet è impossibile utilizzare un solo protocollo di routing: se ogni nodo dovesse aggiornarsi sullo stato dell’ intera rete, l’intero traffico sarebbe occupato solamente da pacchetti di aggiornamento. Per risolvere questo problema si ritiene ogni ISP come un Sistma Autonomo (Autonomous System). Ogni AS utilizza un proprio protocollo di routing interno (Intra-AS, o interdominio, o Interior Gateway Protocol), quindi routers di altri AS possono usare altri protocolli di routing: i protocolli interdominio (o inter-AS o Exterior Gateway Protocol) che gestisce il routing tra i vari AS deve essere però unico.
Gli AS sono interconnessi tra di loro tramite routers speciali chiamati Router Gateway che hanno il compito aggiuntivo d’ inoltrare pacchetti a destinazioni esterne al proprio AS.
Ad ogni AS viene poi assegnato un Autonomous System Number che altro non è che un codice identificativo a 16 bit scelto direttamente dall’ ICANN.
In base a come sono connessi agli altri AS, possiamo classificare i sistemi autonomi come:
- AS Stub: Un solo collegamento verso un’altro AS. Il traffico è generato o destinato all’interno delo stub ma non transita attraverso di esso (tipo una grande azienda o un’università).
- AS Multihomed: Più di un collegaemento verso AS ma non consente il transito di traffico al suo interno. (Una grande azienda)
- AS di transito: E’ collegato a più AS e consente il traffico (network provider o dorsali).
Cominciamo quindi a vedere come funziona il routing intra-dominio parlando del protocollo RIP.
Routing Information protocol
Come già abbiamo detto è un protocollo basato sull’ algoritmo Distance Vector (DV) ed utilizza una metrica di costo basata sul numero di hop.
Ogni hop indica diciamo un router, e il massimo valore che può assumere è 15 mentre con 16 indica infinito. Ogni collegamento quindi ha costo unitario.
Ogni router avrà una tabella di routing dove memorizza tutte le reti all’interno dell’ internetwork. Fra le informazioni che vengono salvate per ogni rete, le più importanti sono:
- Indirizzo della network (o dell’ host).
- La distanza dal router a quella network ( o host).
- Il primo hop da effettuare per arrivare a quella network (o host).
Come abbiamo detto la distanza (o il costo) è misurato in hop. Quindi una la distanza fra un router ed una rete indica per quanti router dovrà passare il datagramma per arrivare a destinazione. Se il router è direttamente connesso ad una rete, allora il valore della distanza è 1.
In RIP, sono permessi un massimo di 15 hops per ogni network o host: un valore uguale a 16 è definito come “Infinito” ed evidenzia che la rete (o l’host) non è raggiungibile.
Funzionamento dell’ algoritmo di routing
Periodicamente, ogni route che utilizza il RIP comunica a tutti i router direttamente raggiungibili, i valori contenuti nella sua tabella di routing.
Quando un router riceve una entry, questa comunica che può raggiungere il router N al costo X. Questo vuol dire che il router che riceve la entry può raggiungere N al costo di X+1 inviando il datagramma al router che gli ha inviato la entry.
Messaggi RIP
Il RIP si basa su un modello client-server e i messaggi scambiabili possono ssere di tipo
- RIP Request: Quando un router viene inserito per la prima volta in una rete, invia una RIP request a tutti i vicini per ricevere le informazioni di routing. Oppure viene utilizzato a fini di diagnosi
- RIP Response (o Advertisement): Come risposta ad una RIP Request, o automaticamente ogni 30 secondi.
Ogni messaggio contiene fino a 25 sottoreti per volta e la distanza del mittente a tali sottoreti. I campi di un messaggio RIP sono:
- Com: Comando, può essere Request o Response,
- Ver: Versione, attualmente è in uso la 2,
- Family: famiglia del protocollo,
- Tag: Informazionisul sistema autonomo,
- Network address: indirizzo di destinazione,
- Subnet Mask: Maschera di sottorete (lunghezza del prefisso)
- Next-Hop Address: indirizzo del prossimo hop,
- Distance: Numero di hop fino alla destinazione.
Il RIP utilizza diversi timer:
- Timer Periodico: viene inviato un messaggio di aggiornamento ogni 25-35 secondi,
- Timer di scadenza: Regola la validità dei percorsi (ogni 180 secondi). Se entro lo scadere del timer non si riceve un aggiornamento il percorso viene considerato scaduto e il suo costo viene impostato a 16.
- Timer per Garbage Collection: Scaduto il timer di scadenza, il router continua a comunicare il router con costo pari a 16. Se entro 120 secondi dal timer di scadenza non viene annunciato un nuovo percorso, viene rimosso dalla tabella.
Se scade il timer di scadenza, il router vicino viene considerato come guasto o spento. Il router propaga l’informazione ai vicini disponibili che a loro volta faranno lo stesso con i loro vicini se la loro tabella d’instradamento è cambiata.
Per evitare di generare loop, si utilizza l’ inversione avvelenata (poisoned reverse): si pone a infinito (ovvero a 16) il valore del costo del percorso che passa attraverso il vicino a cui si sta inviando il vettore. Ovvero se per raggiungere A devo passare per B, C non và a dire a B “ehi guarda che fra te ed A c’è un costo=1” perchè B probabilmente lo sà.
Il RIP viene implementato a livello applicativo sopra all protocollo di trasporto UDP (porta 520). Un processo chiamato routed (route deamon) esegue RIP mantenendo le tabelle di routing aggiornate e inviando messaggi con i processi routed vicini.