Nei sistemi a uniprogrammazione, la gestione della memoria è abbastanza lineare: uno spazio è riservato per il SO (il monitor e il kernel), e una parte è per il processo in esecuzione. Tutto cambia nei sistemi multitasking (o multiprogrammazione) perchè in questo caso, la memoria deve essere suddivisa in modo che lo spazio utente possa mantenere 2 o più processi contemporaneamente.
Vediamo in questa parte, come fa il SO a gestire la memoria.
Possiamo dividere le necessità della gestione della memoria, in cinque punti.
Rilocazione (Relocation)
In un sistema multitasking lo spazio disponibile nella memoria principale viene condiviso con tutti i processi che devono essere eseguiti.
E qui entra in gioco il concetto di rilocazione: un processo, dopo essere stato swappato nella memoria secondaria, deve poter essere ricaricato in memoria principale in un’area diversa da prima a seconda della disponibilità.
Questo perchè altrimenti sarebbe un fatto molto limitante per la gestione dei processi. Ad ogni modo, il SO deve poter conoscere e capire ogni indirizzo del processo: tipo deve conoscere la posizione dell’ process control information.
Visto che è proprio lui a gestire la memoria, riesce facilmente a reperire gli indirizzi di cui ha bisogno: in ogni caso comunque, il processore assieme al SO devono gestire il fatto che i programmi puntano ad indirizzi di memoria logici e che per essere utilizzati devono essere prima tradotti in indirizzi fisici che corrispondono alla reale posizione del dato.
Protezione
In verità questa necessità è gestita dall’ hardware. A causa della necessità della rilocazione, non sappiamo fino al tempo di esecuzione il contenuto della memoria principale e dove punta l’ indirizzo di un processo: in ogni caso, questo non può accedere ad aree di memoria occupate da altri processi (e meno che mai dal sistema operativo).
A tempo di compilazione, è impossibile da prevedere (ripeto, a causa della necessità di rilocazione) a tempo di esecuzione potrebbe pensarci il SO: ma ti immagini a dover controllare se il posto dove punta un indirizzo è un’area protetta o meno? Ovviamente il costo (in tempo di esecuzione) sarebbe troppo proibitivo. Per questo motivo, come detto fin da subito, la protezione della memoria necessita di un supporto hardware.
Condivisione
Al di là della protezione, alcuni processi devono poter accedere alle stesse aree di memoria: magari perchè stanno lavorando sullo stesso problema.
Per questo motivo, la protezione deve essere abbastanza flessibile da permettere la condivisione di memoria ma abbastanza intelligente da bloccare accessi non autorizzati.
Organizzazione logica
Nonostante la visione della memoria del computer come una lunga serie di codice binario si avvicini molto alla realtà, non è in questo modo in cui i programmi sono costruiti: La divisione modulare dei programmi, permette di raggiungere diverse ottimizzazioni:
- I moduli possono essere scritti e compilati indipendentemente e le interferenze possono essere risolte a run-time.
- Si possono implementare diversi tipi di protezione (sola lettura, sola esecuzione) per ogni modulo.
- E’ possibile introdurre meccanismi che permettono la condivisione di spazi di memoria dei singoli moduli.
Tutto questo verrà raggiunto tramite la segmentazione che vedremo fra poco
Organizzazione fisica
E’ possibile vedere la memoria come una piramide:
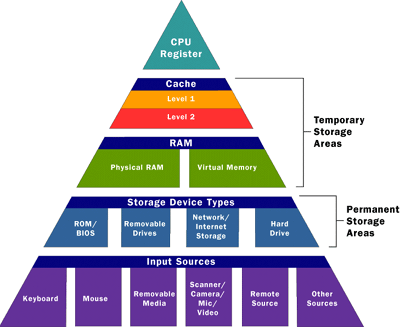
C’è un livello di memoria principale dove vengono caricati i dati e i programmi che sono attualmente in esecuzione, e una memoria secondaria dove vengono salvati i dati per una archiviazione ” a lungo termine”.
Visto che il programmatore non sà quanta memoria è a disposizione del suo programma al momento dell’ esecuzione, può eseguire una tecnica chiamata overlaying che consiste nel dividere il programma in moduli che possono essere swappati fra le due memoria a seconda del bisogno, oppure si può affidare il problema al SO.
Ed è questo, una delle principali preoccupazioni quando si parla della gestione della memoria.
Partizionamento della memoria
I sistemi operativi moderni, sfruttano un sofisticato schema chiamato Memoria Virtuale che utilizza i concetti di Segementazione (Segmentation) e Pagine (Paging).
Per semplificare quindi il discorso sulla memoria virutale, introduciamo alcune tecniche di suddivisione della memoria che ci permetteranno di capire molto più facilmente il discorso sulla memoria virutale.
Partizionamento fisso
In questo schema di gestione della memoria, assumiamo che il SO occupa una regione di memoria prefissata e il resto della memoria è disponibile per l’uso ai processi.
Il sistema più semplice per gestire questa memoria disponibile, è dividerla in blocchi di memoria limitati di lunghezza fissa.
Dimensione della partizione
La partizione può essere suddivisa in due modi:
- Dimensioni uguali
- Dimensioni diverse
Nello schema a dimensioni uguali la memoria è divisa in blocchi di dimensione uguale (es: blocchi da 8mb) ma in questo caso sorge un problema:
- Se il processo occupa più spazio di quello offerto dal blocco (es: 9mb) il programmatore deve utilizzare la tecnica di overlaying vista poco fà.
- Se invece occupa meno spazio di quello disponibile, c’è uno spreco che è chiamato frammentazione interna.
Un’altra soluzione quindi, è quella di creare partizioni di dimensioni diverse(es: 8mb, 13mb, 16mb, 24mb) in modo da cercare di riddure la frammentazione interna.
Algoritmi di posizionamento
Per lo schema a dimensioni uguali, l’algoritmo è semplice: dove c’è uno spazio libero si inserisce il processo. Per la suddivisione in blocchi di dimensione variabile possiamo:
- Creare una coda per ogni blocco di memoria in modo da infilarci il processo di dimensione più simile (in modo da riddure la frammentazione interna)
- Creare una coda generale, e sistemare il processo nel primo blocco disponibile in cui c’entra.
Nel primo tipo, se per esempio abbiamo due processi (A,B) grandi 7 mb e in memoria un solo blocco da 8mb occupato da A ed uno da 10mb libero, per essere eseguito B dovrà aspettare di essere sostituito con A nonostante ci sia spazio sufficiente per ospitarlo.
Partizionamento Dinamico
Il partizionamento dinamico risolve alcuni dei problemi del partizionamento statico ma, purtroppo, ne introduce degli altri.
Più precisamente, risolve il problema della frammentazione interna: se un processo è grande 7mb, uno spazio della stessa dimensione viene preparato in memoria.
Quello che si crea però, è la frammentazione esterna:

Con il partizionamento dinamico quando si liberano delle aree di memoria che però non sono contigue e di piccole dimensioni, non potranno essere utilizzate dagli altri processi (se non entrano in questi buchi).
Un modo per risolvere questo problema, è la compattazione (compaction): ogni tot di tempo, il sistema operativo compatta i blocchi in modo da disporli contingui e da attappare i buchi (frammentazione esterna) che si vanno a creare.
Algoritmi di posizionamento
Per questo sistema, che è già più complesso del precedente, generalmente si sceglie fra tre algoritmi:
- Best–Fit: Scannerizza tutta la memoria e inserisce il processo nell’ area di memoria in cui c’entra meglio (Es: processo da 7 mb, trova due buchi uno da 10 mb e uno da 8mb lo inserisce in quello da 8mb)
- First–Fit: Infila il processo nella prima area di memoria disponibile sufficiente a contenere il processo.
- Next–Fit: Comincia a scannerizzare la memoria dalla posizione dell’ ultimo processo inserito, e appena trova uno spazio sufficiente a contenerlo inserisce il processo.
Su base sperimentale, si è visto che l’algoritmo migliore è il FirstFit: questo perchè, a differenza del BestFit, è quello che permette di ridurre al meglio la frammentazione esterna (ES: processo da 7mb, inserito in uno spazio da 8mb crea 1mb di frammentazione esterna).
Buddy System
Come abbiamo visto, sia il partizionamento statico che quello dinamico hanno dei pregi ma anche grossi difetti. Un compromesso fra i due sistemi, si chiama BuddySystem.
Nel sistema Buddy (buddy vuol dire tipo “amico”) i blocchi di memoria sono disponibili in dimensioni di 2k con L<= K <= U, con
- 2L Il minore blocco di memoria allocato,
- 2U Il più grande blocco di memoria allocato
Vediamo quindi come funziona: all’ inizio lo spazio disponibile all’allocazione è di dimensione 2U: Se un processo richiede spazio s, si verifica che:
2U-1 <s <= 2U
Se si verifica, allora lo spazio viene allocato. Altrimenti, Il blocco viene diviso in due blocchi di dimensione uguale grandi 2^U-1.
E si ripete la verifica:
2U-2 <s <= 2U-1
Se si verifica, lo spazio per s viene allocato. Altrimenti si ridivide in due blocchi di dimensione uguale finchè non troviamo uno spazio di memoria che verifichi questa condizione.
(Per chiarire le idee, guarda la tabella su wikipedia)
Relocazione
Prima di vedere come funziona il paging, parliamo brevemente degli indirizzi: ogni volta che un processo viene swappato dalla memoria a meno che non sia un sistema di partizionamento statico con una queque per ogni partizione, il processo potrebbe venir caricato in memoria centrale in una locazione differente ogni volta.
Teoricamente, ogni volta poi dovremmo modificare il codice sorgente e aggiornare le referenze agli indirizzi a cui puntano le istruzioni all’ interno del processo.
Col termine relative address, si intende un tipo di indirizzo logico in cui si conosce la posizione partendo da una locazione di memoria conosciuta. Quello che succede con gli indirizzi relativi, è che vengono sommati col base register che indica l’ inizio del processo.
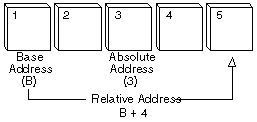
In questo modo, cambiando la posizione ed aggiornando solo il base register, possiamo sapere dove puntano gli indirizzi all’ interno del programma senza doverli aggiornare ogni volta.
Col termine indirizzo logico si intende una posizione in memoria che non corrisponde per forza alla reale posizione del dato, prima infatti bisogna effettuare una traduzione in un indirizzo fisico che invece punta alla reale posizione del dato.
[divider_top]
Paging
Sia il partizionamento a dimensione fissa, che quello a dimensione dinamica hanno dei problemi: il primo inceppa in problemi di frammentazione interna, il secondo in frammentazione esterna.
Ma mettiamo caso che la memoria principale fosse suddivisa in partizione di dimensioni uguali ma relativamente piccole, e che anche i processi venissero suddivisi in parti di dimensione relativamente piccola. Ebbene, le singole parti che compongono un processo vengono chiamate Pagine (pages) e possono essere assegnate nelle piccole partizioni in cui la memoria è suddivisa che prendono il nome di Frames (o page frames). In questo schema, non esiste la frammentazione esterna e la frammentazione interna riguarda l’ultima parte del processo rendendola molto piccola.
 Col paging, i processi non devono per forza occupare un’area di memoria contigua: per tenere traccia della posizione di ogni chunks (parte) del processo, il sistema operativo crea per ognuno di essi una tabella (page Table) dove si segna la posizione di ogni pagina nella memoria principale.
Col paging, i processi non devono per forza occupare un’area di memoria contigua: per tenere traccia della posizione di ogni chunks (parte) del processo, il sistema operativo crea per ognuno di essi una tabella (page Table) dove si segna la posizione di ogni pagina nella memoria principale.
Inoltre si tiene anche una tabella contenente i frame di memoria utilizzabili.
Per rendere lo schema del paging conveniente, vengono utilizzate per la dimensione delle pagine multipli di 2. In questo modo, è facile dimostrare che l’ indirizzo relativo è uguale all’ indirizzo logico.
Se abbiamo pagine di dimensione 1024B = 1KB abbiamo bisogno di 10 bit di indirizzamento (per scegliere il byte). Se i nostri indirizzi sono a 16 bit, ci rimangono 6 bit da usare come index per la scelta della pagina all’interno della pagetable: 26 = 64 pagine che può avere ogni processo.
Per tradurre da indirizzo logico a fisico, la questione è facile: sapendo questa suddivisione (n = 6 = numero di pagina e m=10 = offset) un indirizzo è quindi composto da n+m.
- Prendiamo i primi n bits delll’ indirizzo logico
- Lo usiamo come indice all’ interno della tabella delle pagine e troviamo il numero di frame, k
- L’ indirizzo fisico è formato da k unito a m.
Segmentazione
Un programma può essere suddiviso usando la segmentazione, dove un programma e i suoi dati sono divisi in diversi segmenti che possono anche non essere di dimensioni fisse (anche se comunque c’è un limite massimo per segmento).
Come nel paging, anche quì l’indirizzo logico è formato dal numero di segmento e l’offset. La differenza principale fra la segmentazione, che usa partizioni di dimensioni differente, e il partizionamento di dimensioni dinamiche; è che la segmentazione anche la segmentazione richiede che il processo sia totalmente caricato in memoria, ma è possibile caricarlo in locazioni non contigue.
La segmentazione, per come definisce i blocchi, non soffre di frammentazione interna: a differenza del paging però, ed essendo simile al partizionamento dinamico, soffre purtroppo di frammentazione esterna: col fatto che il processo è diviso in segmenti però, dovrebbe essere minore.
Le pagine poi sono invisibili al programmatore: il discorso cambia con la segmentazione. Volendo per mantenere la modularità è possibile dividere i programmi (e i moduli che lo compongono) e i dati in segmenti diversi: l’ unico problema è che il programmatore deve conoscere la dimensione massima dei segmenti.
Un’altro problema della segmentazione, è che a differenza del paging non esiste una relazione diretta fra indirizzo logico e fisico. Anche con essa vi è una tabella dei segmenti che però oltre a fornire l’ indirizzo di inizio del segmento in memoria, deve provvedere a fornire anche l’ indirizzo di fine del segmento. Quest’ultimo dato deve essere usato per controllare la validità dell’ indirizzo (ovvero che rientri nel segmento).
Per tradurre da logico a fisico, e dividendo l’ indirizzo logico in n+m = 16 bits dove n = 4 = numero di segmento e m = 12 = offset:
- Estraiamo i primi n bits dall’ indirizzo logico;
- Troviamo il numero di segmento come index nella tabella dei segmenti e troviamo l’inizio del’ indirizzo fisico del segmento
- Lo compariamo con l’offset (ovvero con m) per vedere se è un indirizzo lecito,
- L’ indirizzo fisico è dato dalla somma dell’inizio dell’ indirizzo fisico più l’offset del segmento.

Pingback: [Sistemi Operativi] Memoria Virtuale e Translation Lookaside Buffer | InformaticaLab Blog