In questa parte articolo vedremo che cos’è la Memoria Virtuale e come il SO la implementa e la sfrutta.
Nell’ articolo precedente, abbiamo parlato di Simple Paging e Simple Segmentation: continuiamo a parlare di come viene gestita la memoria, introducendo la Memoria Virtuale e il Translation Lookaside Buffer.
Paging e Segmentazione: Una grande innovazione
Dopo aver visto tutti i problemi che derivano dal suddividere la memoria in blocchi, siamo giunti piano piano a due metodi:
- Il Paging: dividiamo la memoria in blocchi molto piccoli (chunks) che risultano in nessuna frammentazione esterna, e una piccola frammentazione interna (solo dell’ ultimo chunk di ogni processo).
- La Segmentazione: dividiamo la memoria in blocchi di dimensione dinamica (eliminando la frammentazione interna) ma che possono causare quindi frammentazione esterna (come il partizionamento dinamico).
I punti di forza di entrambe le metodiche, sono:
- L’ utilizzo di indirizzi logici: la risoluzione dinamica degli indirizzi da logici a fisici, permette ad un processo di trovarsi in posti diversi in momenti diversi.
- La contiguità: Non è richiesta la contiguità del processo. Una volta suddiviso in blocchi, ogni parte viene allocata nella memoria dove c’è spazio.
Partendo però da questi due presupposti, possiamo aggiungere una miglioria che viene quasi di conseguenza: non tutte le parti (sia segmenti che pagine) di un processo devono per forza trovarsi in memoria contemporaneamente, ma solo le parti necessarie al processo per essere eseguito.
[three_fifth]Vediamo quindi quello che succede parlando in maniera generale, ed analizzando dopo nel dettaglio le parti che non abbiamo ancora visto:
- Il processo è in esecuzione: le cose proseguono normali come abbiamo visto negli articoli passati, finchè vengono richiesti indirizzi che puntano al resident set.
- Se viene richiesto un indirizzo che non è presente nel resident set, viene generato un interrupt: il processo viene messo nello stato blocked e il SO esegue una richiesta di lettura I/O.
- Una volta caricata la parte richiesta, c’è un interrupt da parte dell’ I/O e il controllo torna al SO che sposta il processo dallo stato blocked, allo stato ready.
[/three_fifth]
[two_fifth_last][info_box]
La porzione di un processo che si trova nella memoria principale in un dato momento è chiamata insieme residente (resident set) del processo.[/info_box][/two_fifth_last]
Questa nuova aggiunta, cosa comporta?
- Più di un processo può essere mantenuto in memoria principale: visto che carichiamo solo parti di ogni processo, c’è spazio per allocare più processi!
- Un processo può essere più grande di tutta la memoria principale: Una delle più grandi restrizioni nel mondo dell’ informatica è aggirata. Invece di incaricare il programmatore di dividere il suo programma in varie parti, il lavoro è lasciato al SO e alla memoria virtuale.
La memoria in cui risiedono i programmi in esecuzione, è la memoria principale (main memory) e chiamata memoria reale.
Il programma e il programmatore però, vedono molta più memoria: questo succede grazie al supporto della memoria secondaria, e questo tipo di memoria percepita dal programma è chiamata appunto “virtuale“.
C’è anche da dire una cosa: come fà il SO a scegliere quale pezzo togliere e quale inserire nella memoria? Quello che può succedere è che un programma faccia riferimento ad una parte del processo che è appena stata rimossa dalla memoria centrale. Questo porta al trashing: il sistema spende la maggior parte del tempo a spostare pezzi di programmi dalla memoria che ad eseguirli.
Per ovviare a questo problema, esistono degli algoritmi complessi basati in parole povere sul cercare di azzeccare quale parte del processo verrà utilizzato (li vedremo meglio più avanti).
Per creare la memoria virtuale, abbiamo bisogno di due cose:
- Un Hardware per gestire gli schemi del paging/segmentazione
- Un Software, offerto dal SO, che permetta di fare degli swap (scambi) vantaggiosi
Struttura della tabella delle pagine
La memoria virtuale, anche se funziona anche con la segmentazione, è di solito associata alla paginazione ed è da questa che comincieremo a parlare.
L’altra volta abbiamo visto che ogni processo ha una propria tabella della pagine. Ogni riga contiene il numero di frame corrispondente nella memoria fisica.
Anche per creare la memoria virtuale, abbiamo bisogno di una tabella delle pagine: normalmente si associano in una unica tabella ogni processo.
Per gestire anche la memoria virtuale però, abbiamo bisogno di altri dati che andranno a riempire ogni entry della tabella:
- Un bit P: Present, se è asserito vuol dire che la pagina è presente in memoria centrale
- Un bit M: Modify, se è asserito vuol dire che la pagina è stata modificata e và ricaricata in memoria – altrimenti in caso di sostituzione viene semplicemente sovrascritta.
- Altri bit di controllo: ad esempio, se la protezione e la condivisione sono gestiti a livello di pagine verranno implementate nella tabella.
La dimensione della tabella delle pagine, è di grandezza variabile (a seconda del programma): per questo motivo non possiamo aspettarci di poterla contenere all’ interno dei registri del processore.
Quello che succede invece, è che quando un processo è in esecuzione il processore si salva in un registro l’ indirizzo di partenza della tabella delle pagine, a cui viene sommato il numero di pagina dall’ indirizzo virtuale. Viene creato l’ indirizzo fisico ed effettuata la richiesta per la pagina. Graficamente:
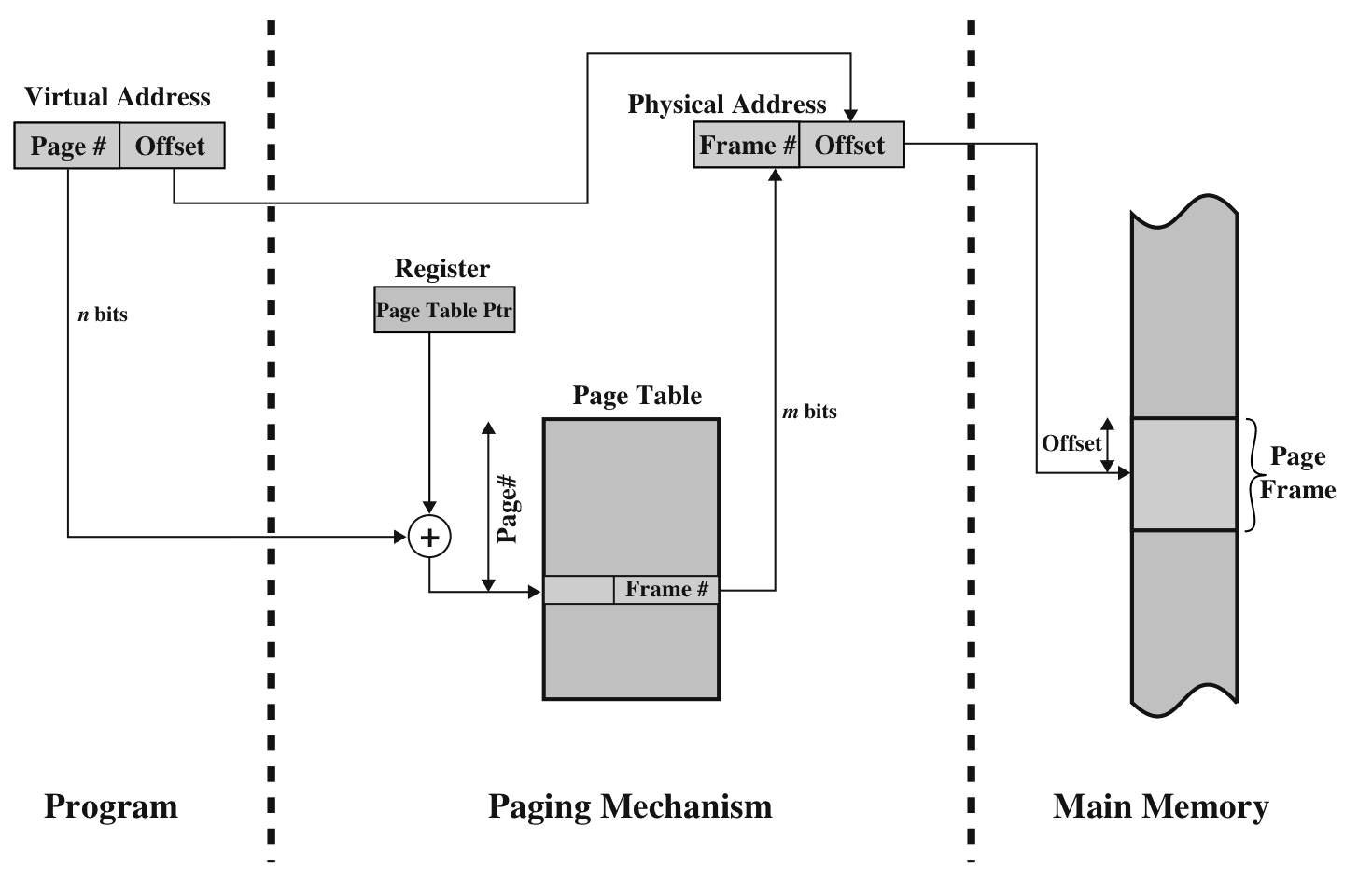 Come abbiamo detto, una tabella delle pagine può diventare molto grande. Per questo motivo, i moderni SO lo trattano come se fosse un dato in memoria: anche esso è soggetto a paging, e swappato dalla memoria principale a secondaria a seconda di quando ne abbiamo bisogno.
Come abbiamo detto, una tabella delle pagine può diventare molto grande. Per questo motivo, i moderni SO lo trattano come se fosse un dato in memoria: anche esso è soggetto a paging, e swappato dalla memoria principale a secondaria a seconda di quando ne abbiamo bisogno.
Per realizzare ciò, si utilizza una tabella delle pagine, che punta alle tabelle delle pagine che a loro volta puntano all’ indirizzo fisico (Two Level Hierarchical Page Table).
TLB – Translation Lookaside Buffer
Se all’ inizio ogni indirizzo virtuale causava due accessi in memoria (uno per caricare la tabella delle pagine appropriata, uno per caricare i dati) con lo schema della memoria virtuale i tempi di accessi sarebbero raddoppiati.
Per aggirare questo grosso problema, la memoria virtuale viene implementata sfruttando una memoria cache ad alta velocità per cachare le entries delle tabelle: il Transaltion Lookaside Buffer, o TLB.
Questa cache funziona come tutte le altre cache (ho l’articolo pronto, se ancora non lo vedi linkato quì lascia un commento o cercalo nel blog!) ma contiene le entries più usate di recente.
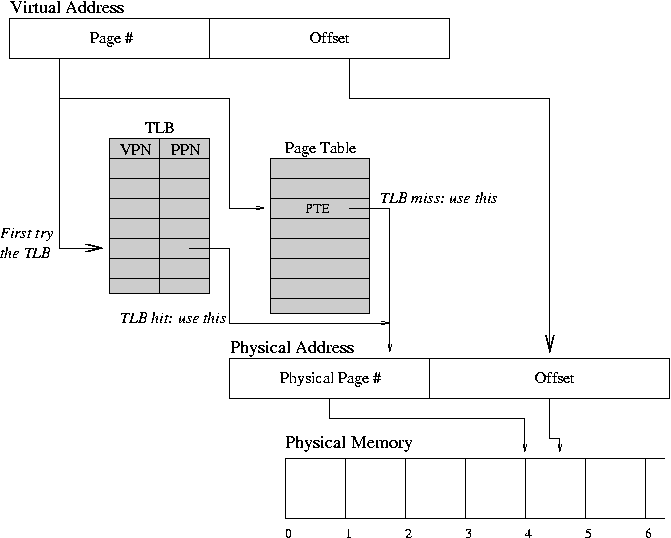
Quello che avviene quindi è:
Dato n indirizzo virtuale, il processore esamina la TLB. Se è un HIT (la tabella è presente) allora estrae il numero del frame e crea l’indirizzo reale.
Altrimenti, se c’è una MISS, il processore utilizza il numero di pagina come indice della tabella delle pagine, esamina la corrispondente entry:
- Se p è asserito: Il dato è presente in memoria principale, crea l’indirizzo reale e richiede il dato. Aggiorna la TLB con questa entry.
- Se p non è asserito: Il dato non è presente in memoria principale, è c’è un Page Fault. Il SO riprende in mano la situazione richiedendo il dato dalla memoria secondaria ed aggiornando la tabella delle pagine.
Dimensione delle pagine
Adesso affrontiamo un’altro argomento importante: qual’è la dimensionemigliore per le pagine? I fattori da considerare sono diversi, il primo fra tutti è la frammentazione interna: più le pagine sono piccole, minore sarà la frammentazione interna. D’altra parte però, più le pagine sono piccole e piùpagine saranno necessarie a processo che causano quindi tabelle delle pagine più grandi.
Tabelle delle pagine più grandi causano (quando usiamo molto la multiprogramazione) i doppi page fault che abbiamo visto poco fà parlando della TLB.
Software del Sistema Operativo
La scelta di implementazione del sistema operativo dipende da tre scelte progettuali:
- Usare o no le tecniche di memoria virtuale
- L’ uso del sistema di paging o quello di segmentazione o entrambi
- L’ uso di algoritmi che operano a livello di gestione della memoria.
Vediamo tutte le varie policy che deve implementare un sistema operativo:
Politica di Fetching
Questa policy determina quando una pagina dovrebbe essere caricata o meno in memoria principale. Possono essere di due tipi:
- Demand paging: una pagina viene caricata in memoria solo quando richiesta. Secondo il principio di località, dopo molti pagae fault iniziali di quando il processo deve essere caricato in memoria il numero di page fault dovrebbe diminuire.
- Prepaging: Oltre alle pagine richieste, vengono caricate in memoria principalre anche le pagine successive a quella richiesta in modo da exploitare il fatto che i dispositivi di archiviazione secondari (dischi fissi) richiedono tempo a spostarsi sul dato richiesto.
Politica di piazzamento
Le politche di piazzamento le abbiamo già viste e discusse: possono essere Best-fit, first-fit ecc. In un sistema che utilizza il paging o il paging unito alla segmentazione, la politica di piazzamento non è di grande importanza. Questo per la presenza dell’ hardware che traduce gli indirizzi che rende il sistema in ogni caso molto efficiente.
Politica di sostituzione
Con politica di sostituzione, si intende quale pagina presente in memoria centrale, dovrebbe essere sostituita in caso in cui la memoria sia piena e bisogna caricare un dato dalla memoria secondaria. Quale pagina dovremmo sostituire? E perchè?
Tutti gli algoritmi di sostituzione, sfruttando il principio di località, cercano di predire il futuro cercando di sostituire una pagina che non verrà referenziata a breve. Per realizzare ciò quindi, dobbiamo anche tenere in considerazione l’overhead per il calcolo che deve essere quindi un compromesso conveniente (se ci vuole più tempo a calcolare la pagina da sostituire che a ricaricarla una seconda volta è ovviamente scoveniente).
Prima di parlare dei vari algoritmi di sostituzione, bisogna accennare al fatto che alcune pagine sono bloccate (frame locking). Ad esempio, le funzioni del kernel si trovano in pagine bloccate che non devono e non possono essere rimosse dalla memoria centrale.
La prima politica di sostituzione, è chiamataq Optimal: questa si basa sul fatto che il sistema operativo riesca a conoscere le future richieste di referenze e sà quindi di volta in volta qual’è la pagina migliore da sostituire.
Questo algoritmo non è ovviamente realizzabile: il SO non può sapere dall’ inizio le referenziazioni di tutto il processo, ad ogni modo rappresenta un’ utile confronto per capire se il nostro algoritmo è buono o no.
Un’ algoritmo che si avvicina a quello Optimal, è la politica di LRU (Least Recently Used) che si basa sul principio di località: di volta in volta, và sostituita la pagina usata meno di recente.
Purtroppo questo è un’algoritmo molto complesso da realizzare. Una alternativa facilmente realizzabile ma non molto efficiente è quello sfruttare una coda FIFO (First In First Out): andiamo a sostituire la pagina che è stata inserita meno di recente.
A funzionare funziona, ma non sfruttiamo molto il principio di località. Quello che ci viene incontro è la politica Clock che sfrutta il meglio di FIFO e di LRU e da cui poi discendono praticamente tutti gli algoritmi più usati e funziona così: prima di tutto viene aggiunto un bit alla tabella delle pagine “Use” che se 1 indica che di recente è stata usata, e poi un buffer circolare dove vengono inserite le pagine.
La prima pagina (chiamiamola 34) viene caricata nel buffer circolare dopo un page fault, il suo bit use viene impostato a uno e un puntatore viene impostato sulla pagina successiva. Una volta che il buffer circolare si è riempito, quindi la pagina a cui punta il puntatore è la pagina 34, tutte le pagine nel buffer vengono impostate con Use=0.
La prossima pagina da sostituire, è quella indicata dal puntatore (quindi la 34) a meno che il suo bit Use non venga impostato ad 1 prima di una nuova richiesta di sostituzione: in quel caso il puntatore cercherà la prossima pagina con use=0.
Per aumentare ulteriormente l’efficienza, si usa aggiungere un bit Modified che se asserito, indica che la pagina è stata modificata e quindi prima di essere sostituita deve essere aggiornata con una richiesta I/O. Altrimenti può essere rimossa senza problemi. Nel clock policy si cercano prima le pagine con use=0 e modified=0. Poi le pagine con use=0 e modified=1. Se non si trovano si impostano a 0 tutti gli use e si sostituisce la pagina più vecchia.