Vediamo nel dettaglio come funzionano i protocolli User Datagram Protocol e Transmission Control Protocol.
Cominciamo parlando di UDP, e vediamo altri protocolli del livello di trasporto più semplici fino ad arrivare al TCP.
Protocolli di trasporto: User Datagram Protocol
Lo UDP (RFC 768) è un protocollo di trasporto inaffidabile e privo di connessione.
Esso fornisce i servizi di:
- Comunicazione tra processi utilizzando le socket
- Multiplexing/Demultiplexing dei pacchetti
Non fornisce alcun controllo di flusso, di errori (tranne uno, il checksum), e controllo di congestione.
Datagrammi UDP
Non vi è come abbiamo detto già in precedenza, nessun flusso di dati: ovvero il processo mittente non può inviare un flusso di dati e aspettarsi che UDP lo suddivida in datagrammi correlati come avviane con TCP.
I processi devono inviare richieste di dimensioni sufficientemente piccole per essere inserite ciascuna in un singolo datagramma utente.
Solo i processi che usano messaggi di dimensioni inferiori a 65507 byte (che sarebbero 65535 byte – 8 byte di intestazione di UDP e 20 byte di intestazione aggiunti da IP) possono utilizzare il protocollo UDP.
Gli 8 bit di intestazione di UDP sono:
- Numero di porta origine,
- Numero di porta destinazione
- Lunghezza in byte del segmento UDP inclusa l’intestazione
- Checksum,
A completare il datagramma UDP manca solo il messaggio del livello di applicazione (es: DNS).
Visto che non esiste un controllo di flusso nè di congestione, il mittente può inviare pacchetti uno dopo l’altro senza interessarsi del destinatario.
Checksum UDP
Come controllo degli errori, con UDP abbiamo solo questo: il checksum. Il suo obiettivo, è quello di rilevare gli “errori” (dove con errori intendiamo i bit alterati) nel segmento trasmesso.
I passaggi per il calcolo sono:
- Divide il messaggio in half-word da 16 bit
- Il valore del checksum viene impostato a zero
- Le half-word del messaggio compreso il checksum, viene sommato usando l’addizione in complemento ad uno
- Viene fatto il completamento ad uno della somma e il risultato è il checksum.
- Viene inviato il segmento compreso di checksum,
- Il messaggio viene ricevuto dal destinatario,
- Lo divide in half-word
- Tutte le parole vengono sommate usando l’addizione complemento ad uno
- Viene fatto il complemento ad uno della somma e il risultato diventa il nuovo checksum
- Se il valore è 0 allora il messaggio viene accettato, altrimenti viene scartato.
Grazie al fatto che non deve eseguire il setup della connessione, UDP si presta molto bene a servizi che richiedono velocità. Viene usato anche dal DNS che quando effettua una query, se non riceve risposta dopo tot tempo rinvia la richiesta.
Protocollo Stop-And-Wait
E’ un protocollo orientato alla connessione che possiede il controllo di flusso e controllo degli errori.
Il mittente invia un pacchetto alla volta e ne attende l’ack prima di spedire il successivo.:
Quando il pacchetto arriva al destinatario, vien calcolato il checksum:
- Se è giusto, viene inviato indietro un ack
- Se è sbagliato, viene scartato senza informare il mittente.
Per capire se un pacchetto è andato perso, il mittente utilizza un timer.
Implementa il controllo degli errori tramite numero di sequenza, l’ack e il timer e il controllo di flusso (non spedisce infatti più di un pacchetto alla volta).
Per questo protocollo, sono sufficienti solo due numeri di sequenza (0 e 1). Per convenzione, il numero di riscontro corrisponde al numero di sequenza del prossimo pacchetto atteso dal destinatario.
Efficienza dello stop-and-wait
Consideriamo il prodotto rate*ritardo: se il rate è elevato e il ritardo è lungo lo stop and wait risulta molto inefficiente!
- Rate = 1Mbps
- Ritardo di andata e ritorno di 1 bit = 20 ms
- Per pacchetti di dimensione 1000bit:
- rate*ritardo=(1×106)x(20×10-3) = 20000 bit che potrebbero essere inviati, mentre ne usa solo 1000.
Quindi il coefficiente di utilizzo del canale è 1000/20000 = 5%. Decisamente inefficiente
Protocolli con pipeline
Visto che il precedente protocollo è molto inefficiente, introduciamo un sistema per migliorarlo: il pipelining.
Con il pipelining il mittente ammette più pacchetti in transito, ancora da notificare: l’ intervallo dei numeri di sequenza deve essere incrementato e il buffer dei pacchetti presso il mittente e/o ricevente.
Esistono due protocolli che sfruttano il pipelining: il Go–Back–N e la ripetizione selettiva.
Go-Back-N
Nel Go-Back-N i numeri di sequenza sono calcolati in modulo 2m dove m è la dimensione del campo “numero di sequenza” in bit.
L’ ack indica il numero di sequenza del prossimo pacchetto atteso. Introduce poi l’ Ack Cumulativo, ovvero tutti i pacchetti fino al numero di sequenza indicato nell’ ack sono stati ricevuti correttamente.
Quindi, quando il ricevente invia un AckNo=7 significa che ha ricevuto correttamente i pacchetti fino al 6, e il prossimo che si aspetta è il 7.
Finestra di invio
La finestra di invio è un concetto astratto che definisce una porzione immaginaria di dimensione massima 2m-1 con tre variabili Sf, Sn, Ssize.
La finestra di invio può scorrere uno o più posizioni quando viene ricevuto un riscontro privo di errori con ackNo maggiore o uguale a Sf(Indice del primo pacchetto non riscontrato) e miniore di Sn(Prossimo pacchetto da inviare) in aritmetica modulare.
Per ovvi motivi, la dimensione della finestra di invio deve essere massimo 2^m-1
Finestra di ricezione
A differenza di quella di invio, la sua dimensione è 1. Questo perchè il destinatario è sempre in attesa di uno specifico pacchetto qualsiasi pacchetto arrivato fuori sequenza viene scartato.
La finestra quindi può scorrere di una sola posizione Rn = (Rn+1) mod 2m
Timer e Rispedizione
Al pacchetto non riscontrato, viene associato un timer. Una volta scaduto questo timer, il mittente vai indietro a N (go-back-n) dove N è l’ultimo pacchetto che ha ricevuto riscontro, e li rinviia tutti.
Ripetizione Selettiva
Mentre in GBN per un solo pacchetto perso si ritrasmettono tutti i successivi già inviati, con la ripetizione selettiva (come si intuisce dal nome) il mittente ritrasmette solo i pacchetti per i quali non ha ricevuto un ACK. In questo protocollo quindi, è necessario un timer per ogni pacchetto non riscontrato ed il ricevente invia riscontri specifici per tutti i pacchetti ricevuti correttamente.
In questo caso, la finestra di invio e quella di ricezione hanno la stessa dimensione.
[divider_top]
Abbiamo visto finora tutti i vari modi in cui i livelli di trasporto implementano i loro servizi (controllo congestione, ritardi, timeout, ecc) questo per prepararci ad introdurre TCP. Vediamo quindi ancora, come si realizza l’ affidabilità
Piggybacking
Finora abbiamo analizzato meccanismi unidirezionali: io ricevo un dato, invio il riscontro e così via. Ma per migliorare ulteriormente l’efficienza della rete, introduciamo il piggybacking: in pratica quando A invia un pacchetto di dati a B, se c’è spazio in questo include gli ack dei pacchetti precedentemente ricevuti da B.
TCP
Il TCP viene utilizzato per creare connessioni punto a punto e trasmettere in maniera affidabile un flusso di byte in sequenza.
Sfrutta il pipelining ed è full duplex: lo stesso flusso di dati è utilizzato in maniera bidirezionale, ovvero la stessa pipe è usata per ricevere e inviare i dati.
La connessione comincia con l’ handshaking (stretta di mano, consiste nello scambio di messaggi di controllo) che inizializza lo stato del mittente e del destinatario prima di inviare i dati.
Fra le altre cose, implementa anche il controllo di flusso che permette di non sovraccaricare di pacchetti il destinatario.
Il TCP riceve uno stream di byte dal processo mittente ed utilizza il servizio di comunicazione tra host offerto dal livello di rete per trasferire i pacchetti.
Quello che fà, è raggruppare un certo numero di byte in segmenti, aggiunge un’ instestazione e consega al livello di rete per la trasmissione.
Le intestazioni di TCP, variano da 20 a 60 byte e sono:
- URG: Dati urgenti (generalmente non usato)
- Numero di Sequenza e Numero di riscontro: Conteggio per byte di dati (non segmenti!) 32 bit per uno
- PSH: Richiesta di push, Invia i dati adesso ovvero crea e invia subito il segmento che a destizianzione deve essere subito consegnato all’ applicazione,
- ACK: Riscontro valido
- RST: Azzeramento della connessione
- SYN: Sincronizzazione dei numeri di sequenza
- FIN: Chiusura della connessione
- Finestra di Ricezione: Numero di bye che il destinatario desidera accettare (per il controllo di flusso)
- Opzioni: Altre opzioni
Numeri di sequenza e ACK di TCP
Il numero di sequenza è il “numero” del primo byte del segmento nel flusso di byte, mentre l’ ACK è il numero di sequenza del prossimo byte atteso dall’ altro lato. Anche TCP implementa l’ ACK cumulativo.
Il numero di sequenza poi, è scelto casualmente: questo per evitare che un segmento di una precedente connessione ancora presente in rete possa essere interpretato come valido per la nuova connessione.
TCP: Tempo di andata e ritorno e timeout
Connessione TCP
Vediamo adesso come si stabilisce una connessione di tipo TCP fra due host
- Apertura della connessione
- Trasferimento dei dati
- Chiusura della connessione
L’apertura della connessione avviene con il three-way handshake.
Sia il mittente che il destinatario, inviano dati e riscontri in entrambe le direzioni (piggybacking) e cominciano scambiandosi:
- Mittente invia un SYN con un numero casuale al destinatario
- Il destinatario risponde con un SYN con un numero casuale, ed un ACK del numero precedente
- Il mittente risponde con un ACK e i dati che deve inviare.
La chiusura della connessione è solitamente richiesta dal client, oppure può avvenire dal server per lo scadere di un timer.
Per chiudere la connessione, i due host devono scambiarsi due riscontri FIN:
- Il client invia un FIN al server, che replica con un ACK
- Il server appena può (è generato dall’ applicazione) invia un FIN al client, che risponde con un ACK.
Affidabilità e controllo degli errori del TCP
Utilizza come il collega UDP il checksum per riconoscere un segmento corrotto. Utilizza gli ack cumulativi, come già avevamo anticipato, e i timer di ritrasmissione però unico ed impostato sul più vecchio.
I casi che possono accedere per quanto riguarda l’ ACK sono:
- Arrivo ordinato di un segmento con numero di sequenza atteso. Tutti i dati fino al numero di sequenza atteso sono già stati riscontrati -> Attende fino a 500ms l’ arrivo del prossimo segmento. Se non arriva, invia un ACK (ACK delayed).
- Arrivo ordinato di un segmento con numero di sequenza atteso. Un altro segmento è in attesa di trasmissione dell’ ACK -> Invia immediatamente un singolo ACK cumulativo, riscontrando entrambi i segmenti ordinati.
- Arrivo non ordinato di un segmento con numero di sequenza superiore a quello atteso. Viene rilevato un buco -> Invia immediatamente un ACK duplicato indicando il numero di sequenza del prossimo byte atteso.
- Arrivo di un segmento che colma parzialmente o completamente il buco -> Invia immediatamente un ACK, ammesso che il segmento cominci all’ estremità inferiore del buco.
Quando un segmento viene inviato, una copia viene memorizzata in una coda in attesa di essere riscontrato (finestra di invio)
Se il segmento non viene riscontrato può accadere che:
- Scade il timer(è impostato sul primo segmento all’ inizio della coda) -> Il segmento viene ritrasmesso e viene riavviato il timer,
- Vengono ricevuti 3 ack duplicati -> ritrasmissione veloce del segmento senza attendere il timeout.
Controllo del flusso
L’ obbiettivo del controllo di flusso, è quello di non sovraccaricare il destinatario inviando troppi pacchetti troppo velocemente: quello che deve fare quindi è bilanciare la velocità di invio con quella di ricezione a livello di processi del destinatario.
Per farlo, si sfrutta un feedback esplicito del destinatario. Tramite il flag RWND comunica al mittente lo spazio disponibile nella finestra di ricezione.

Controllo della congestione
La congestione avviene quando troppi sorgenti cercano di trasmettere troppi dati, troppo velocemente e la rete non è in grado di gestirli. E’ differente dal controllo di flusso, in quanto in questo caso ci sono:
- Lunghi ritardi a causa dell’ accodamento nei buffer dei router,
- Pacchetti smarriti a causa dell’ overflow nei buffer dei router.
Le cause della congestione sono evidenti: abbiamo un Throughput massimo finchè il carico non raggiunge la capacità della rete. Una volta raggiunto, il ritardo aumenta bruscamente perchè bisogna aggiungere il ritardo di accodamento e quando il carico supera la capacità i buffer si riempiono causando lo scartamento dei pacchetti in eccesso (che devono essere rispediti intasando ulteriormente la rete!).
Con il controllo di flusso, il mittente che invia pacchetti cerca di non sovraccaricare il destinatario con troppi dati: con la congestione invece, ad essere sovraccaricati sono i nodi intermedi ovvero i router.
Anche se è un problema di IP, viene gestito da TCP tramite due approcci:
- End-to-end: nessun supporto esplicito dalla rete, la congestione è dedotta osservando le perdite e i ritardi nei sistemi terminali. Questo è il metodo adottato da TCP.
- Assistito dalla rete: i router forniscono feedback agli end system: con un singolo bit riesce ad indicare la congestione e comunica in modo esplicito al mittente la frequenza trasmissiva.
Per risolvere il problema della congestione, TCP implementa una
Finestra di congestione
Si utilizza il flag CWND (Congestion Windows) che insieme RWND definisce la dimensione della finestra di invio:
Dimensione della finestra = minimo(rwnd,cwnd)
Quindi il mittente si regola:
UltimoByteInviato - UltimoByteConfermato =< Cwnd
Quindi, la frequenza di invio è data da:
Cwnd/Rtt byte/sec
Rilevare la congestione
Gli ACK duplicati e il timeout possono essere intesi come eventi di perdita, ovvero danno indicazione dello stato della rete
- Se gli ACK arrivano in sequenza e con buona frequenza si può inviare e incrementare la quantità di segmenti inviati
- Se ACK duplicati o timeout è necessario ridurre la finestra dei pacchetti che si spediscono senza aver ricevuto riscontri.
Tcp è auto-temporizzante ovvero reagisce in base ai riscontri che ottiene.
Controllo della congestione
L’ idea di base è incrementare il rate di trasmissione se non c’è congestione (ack in sequenza e frequenti), mentre diminuirla se c’è congestione (aumento di segmenti persi).
Per controllare la congestione, l’algoritmo ha tre componenti:
[dropcap2]1[/dropcap2] Slow Start: la CWND inizia a 1MSS e con un rate di spedizione pari a MSS/RTT. Per ogni segmento riscontrato, slow start incrementa di 1MSS la cwnd per ogni segmento riscontrato.
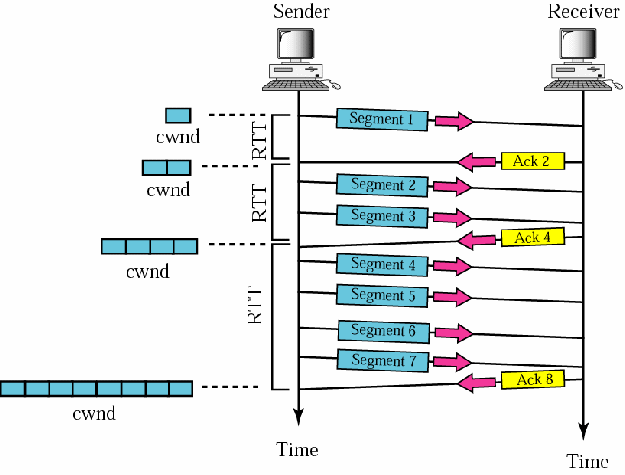
[dropcap2]2[/dropcap2] Congestion Avoidance: Con lo slow start, la CWND continua a crescere finchè non viene perso un pacchetto (sstrheshold = cwnd/2 e cwnd viene impostato a 1) o finchè non raggiunge la ssthresh (slow start threshold – soglia massima raggiungibile).
Si arresta slow start e inizia congestion avoidance:
Per evitare la congestione, si passa da un incremento esponenziale del slow start ad uno lineare. Ogni volta che viene riscontrato l’ intera finestra di segmenti, si incrementa di 1 la CWND. Continuerà ad aumentare linearmente finchè non si rileva una congestione (ovvero a un timeout o 3 ack duplicati).
Congestion Avoidance rimane attivo ed incrementa la CWND finchè non si rileva una congestione, quindi un timeout o 3 ack duplicati.
Al timeout o dopo i 3 riscontri, parte il Fast recovery
[dropcap2]3 [/dropcap2]Fast recovery: è opzionale in TCP e non utilizzato nella sua vecchia versione. Come il Congestion Avoidance aumenta in modo lineare ma solo quando si riceve un riscontro duplicato (ovvero una congestione leggera).
Versioni TCP
Esistono due versioni di TCP:
Thaoe: Considera il timeout e i 3 ack duplicati come congestione e riparte da 1 impostando ssthresh =cwnd/2
Reno: Distingue tra timeout (in questo caso riparte da 1) e 3 ack duplicati (avvia il fast recovery a partire da ssthreshold +3).




Pingback: Netcat: il coltellino svizzero delle reti TCP/IP | InformaticaLab Blog
Pingback: Netcat: il coltellino svizzero delle reti TCP/IP | InformaticaLab