
Abbiamo già introdotto nella parte introduttiva il concetto di processo: cominciamo ad approfondirlo definendo che cos’è un processo.
Un processo, come visto nei precedenti articoli, può essere definito in vari modi:
- Un programma in esecuzione,
- Un’ istanza di un programma in esecuzione sul computer,
- L’ entità che può essere assegnata ed eseguita dal processore.
Per fissare meglio il concetto, possiamo pensare ad un processo come un entità formata da due elementi principali: un codice ed un insieme di dati associati ad esso.
Mentre il processo è in esecuzione, esso è definito da diversi elementi che sono:
- L’ id (identifier): un unico identificatore associato al processo per distinguerlo dagli altri,
- Stato: Se il processo è in esecuzione, è nello stato Esecuzione (running).
- Priority: Il livello di priorità rispetto gli altri processi
- Program Counter: L’ indirizzo della prossima istruzione nel programma che deve essere eseguita,
- Memory Pointers: Includono i puntatori al sorgente del programma e ai dati associati ad esso.
- Contex Data: I dati contenuti nei registri del processore durante l’esecuzione,
- I/O status information: Le richieste di I/O, i dispositivi di I/O assegnati al processo, ed i file che stà gestendo
- Accounting Information: Include diverse informazioni del tipo tempo di esecuzione, limite di tempo di esecuzione e così via.
Tutte queste informazioni vengono salvate al interno di una struttura dati chiamata “Process Control Block” che è creata e gestita dal SO.
Questo tipo di struttura dati, non solo ci permette di implementare gli interrupts, ma ci permette anche di supportare la multiprogrammazione.
Stati dei processi
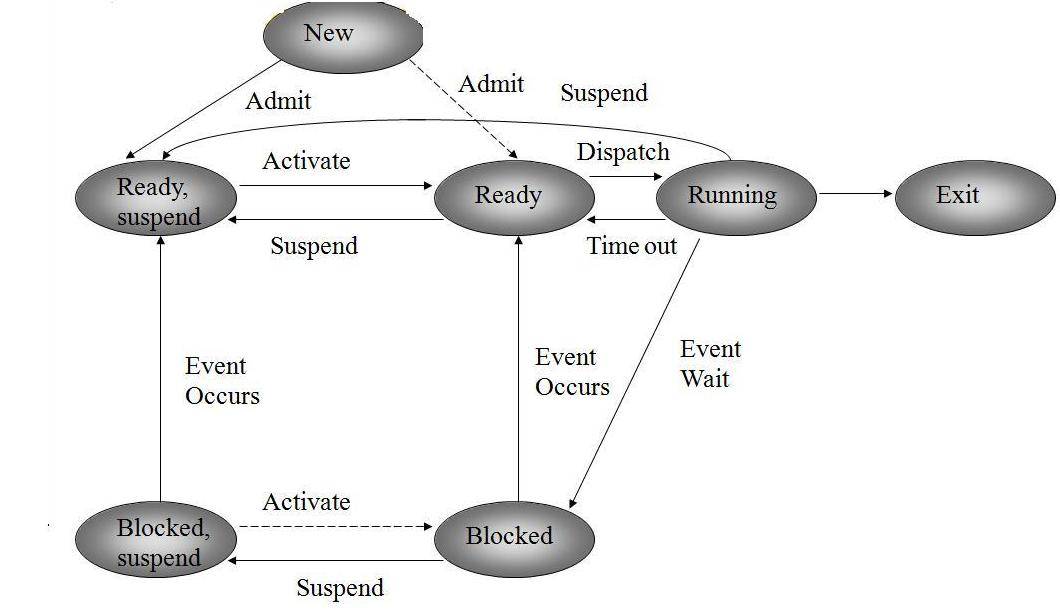
Col termine Dispatcher, intendiamo un programma del sistema operativo che si occupa di scegliere a quale processo deve essere assegnato il processore in un dato momento. Descriviamo questo diagramma per parlare dello stato dei processi.
- Ready: Il processo è in memoria principale e pronto per essere eseguito.
- Blocked: Il processo si trova nella memoria principale in attesa che accada un evento,
- Blocked/Suspend: Il processo si trova in memoria secondaria in attesa di un evento,
- Ready/Suspend: Il processo si trova in memoria secondaria ma è pronto per essere eseguito appena verrà caricato in memoria principale.
In pratica i processi che si trovano in uno stato Suspend si trovano in memoria secondaria, e devono essere Swappati in memoria principale prima di poter essere eseguiti.
Alcuni motivi per cui il processo potrebbe essere spostato nella memoria di Swap sono:
- Swapping: Il SO a bisogno di spazio per eseguire altri processi: sposta quelli con minor priorità in un’area apposita chiamata Area di Swap.
- Altre ragione del SO: Potrebbe swappare un processo per altri motivi suoi, come un sospetto di un errore.
- Per richiesta del utente: Un utente potrebbe richiedere che un processo possa essere sospeso.
- Timing: Un processo potrebbe essere eseguito periodicamente e potrebbe essere sospeso mentre aspetta per il prossimo intervallo.
- Richiesta dal processo genitore: Un processo genitore potrebbe richiedere che il figlio possa essere sospeso.
Descrizione dei processi:
Ogni processo ha bisogno di un certo tipo e quantità di risorse che gli vengano assegnate. Il SO deve quindi non solo tenere traccia delle strutture dei processi, ma anche delle varie risorse: ogni sistema operativo implementa in maniera propria questa organizzazione, in generale comunque quello che fa è creare 4 tabelle:
- Tabelle di memoria: Vengono utilizzate per tenere traccia del contenuto sia della memoria primaria che di quella secondaria ed include: l’ allocazione dei processi nella memoria principale, l’allocazione dei processi nella memoria secondaria, la protezione delle varie aree di memoria e ogni informazione richiesta per gestire la memoria virtuale.
- Tabello di I/O: Usate dal SO per gestire i dispositivi di I/O
- Tabelle dei file: Potrebbe mantenere traccia dei file presenti nella memoria secondaria, compresi il loro stato e i loro attributi. La maggior parte di queste informazioni vengono utilizzate dal sistema di gestione dei file.
- Tabelle dei processi: Contiene dei riferimenti alle process control image che vediamo qui sotto.
Stutture di controllo dei processi (Process Control Structures)
In base al sistema di gestione della memoria che utilizziamo, potremo trovare le Process Control Image contigue o separate nella memoria: Questo insieme di informazioni, sono strutture dati formate da:
- Dati utente: La parte modificabile dello spazio utente. Include i dati del programma, l’ area dello stack utente.
- Programma utente: Il programma da eseguire.
- Stack: Ogni processo ha una o più strutture a pila LIFO (Last In – First Out) associate ad esso. Lo stack viene utilizzato per salvare parametri e indirizzi durante le procedure o le system calls.
- Process Control Block: Già lo abbiamo accennato diverse volte, esso contiene i dati necessari al SO per controllare il processo.
A sua volta, il Process Control Block contiene quattro gruppi di informazioni che, andando avanti con lo studio sui SO, sarà più chiaro il motivo per cui si trovano qui:
- Identificazione del processo: Identificatori numerici che possono essere Identificatore di questo processo (di solito corrisponde all’indice assegnato nella Tabella dei processi vista poco fa), identificatore del utente, identificatore del processo genitore.
- Informazioni sullo stato del processore: il contenuto di tutti i registri, i puntatori allo stack, e i segnali di controllo del processore.
- Informazioni per il controllo del processo (Processo Conrol Information): Contiene:
- Informazioni sullo stato e sullo scheduling: informazioni utilizzate dal SO per lo scheduling dei processi.,
- Data Structuring: Collegamenti in strutture dati a cui appartiene il processo
- Comunicazione interprocesso: Informazioni per la comunicazione fra processi
- Gestione della memoria: Puntatori a segmenti o tabelle di pagine di memoria virtuale assegnate a questo processo
- Privilegi dei processi: I privilegi assegnati al processo, come la possibilità di accedere a speciali aree di memoria
- Utilizzo e controllo di risorse: Tutte le risorse che il processo stà controllando o a cui sono state assegnate.
Creazione di un processo
Dopo aver visto bene com’è strutturato un processo, vediamo i passaggi che il SO deve eseguire per creare un processo.
Prima di continuare, una piccola premessa: i processi possono essere eseguiti in due modalità, user mode e kernel mode.
In kernel mode vengono eseguiti tutti i processi di sistema, mentre in user mode tutti i programmi utente: questo sempre per un fatto di sicurezza dei processi e delle aree di memoria (lo vedemmo già parlando del Monitor).
I passaggi per creare un processo sono:
- Assegnare un id unico al nuovo processo: viene assegnato un ID e aggiunto nella tabella dei processi
- Allocare lo spazio per il processo: questa allocazione può essere di una quantità “standard” da parte del SO, oppure può essere richiesta dal processo o dal processo genitore.
- Inizializzare il process control block: La maggior parte dei campi quì contenuti vengono inizializzati a zero
- Settare i link: Ad esempio, il processo appena creato và assegnato alla coda dei processi nello stato “Ready” oppure “Ready/Suspend”.
- Creare o espandere le altre strutture dati.
Passare da un processo all’altro
Prima di parlare di come il SO riesca a passare da un processo all’altro, dovremmo vedere Quando passare da un processo all’altro.
Il passaggio da un processo all’altro, avviene di solito quando il SO prende possesso del processore. Per farlo, deve esserci una interrupt di sistema.
Queste interrupt, si dividono in Interrupt, e Trap. La divisione si basa sul fatto che il primo capita quando avviene un evento esterno e indipendente dal processo attualmente in esecuzione, l’altro invece avviene quando c’è una condizione di errore o di eccezione.
Quando avviene un interrupt generale, il controllo viene passato ad un interrupt handler (gestore di interrupt) che dopo aver cercato di capire il problema, rimanda il controllo alla parte adatta del SO per riuscire a risolverlo.
Alcuni tipi di interrupt sono:
- Clock Interrupt: Il SO si accorge che il processo ha esaurito il tempo che gli aveva messo a disposizione: per questo motivo viene sostituito con un’altro scelto dal dispatcher.
- I/O Interrupt: Le chiamate ai dispositivi di I/O sono le più lente e gestite in “background”: una volta che la chiamata fatta da un processo ha avuto risposta, il SO deve decidere se portarlo dallo stato ready a quello running o lasciarlo in ready. con una priorità alta.
- Memory Fault: Quando il processore cerca una word nella memoria virtuale che non c’è e che quindi deve essere caricata dalla memoria secondaria a quella primaria. Una volta eseguita l’operazione di caricamento, il processo va nello stato Ready.
Con una Trap invece, un SO determina se la condizione di è un errore o un’eccezione fatale. In questo caso, lo stato del processo passa ad Exit e viene cambiato con un altro processo.
Infine, un altro caso in cui il SO può prendere il controllo è quando un programma esegue una Supervisor Call: ad esempio, il SO solo ha il potere di gestire i dispositivi di I/O per questo motivo se un processo ha bisogno di un dato deve chiederlo al SO.
Cambiamento dello stato di un processo
Adesso vediamo infine i passaggi che il sistema operativo esegue per passare da un processo all’altro (o, più precisamente, per cambiare lo stato di un processo):
- Salva il contesto del processore,
- Aggiorna il Process Control Block del processo in esecuzione (con stato Running). Questo include quindi cambiare il suo stato da Running -> {Ready;Blocked; Ready/Suspend;Exit}
- Sposta il Process Control Block di questo processo nella giusta coda (Ready Blocked ecc)
- Seleziona un’altro processo per l’esecuzione (lo sceglie il dispatcher)
- Aggiorna il Process Control Block del processo selezionato. Incluso lo stato da quello che era a Running
- Aggiorna le strutture dati della gestione della memoria
- Ripristina il contesto del processore a quando il processo era in esecuzione.
Esecuzione di un Sistema Operativo
Parliamo brevemente di come i processi del sistema operativo vengono eseguiti: esistono due tipi di architetture fra cui possiamo scegliere:
- Non-Process Kernel: Esegue i processi kernel al di fuori di ogni processo. Questo vuol dire che il codice del Sistema Operativo è eseguito come un’entità separata e in modalità privilegiata.
- Esecuzione all’interno dei processi: Il codice del sistema operativo viene eseguito all’interno del contesto del processo. Il processo viene eseguito in modalità privilegiata quando esegue il codice del SO.
- Sistema operativo basato sui processi: In questo caso il sistema operativo viene implementato come una collezioni di processi di sistema. E’ ottimo nei sistemi multiprocessore e negli ambienti multi-computer.

