
Cominciamo a vedere che protocolli si trovano sul layer Applicazione, ovvero quello in cima nello stack TCP/IP, introducendo il protocollo HTTP.
Innanzitutto un breve riassunto sulla storia: Internet abbiamo visto che significa InterNetwork, e con la Internet intendiamo la rete delle reti; ed è per questo motivo che si è meritato il nome di WWW: World Wide Web ovvero Grande Ragnatela Mondiale.
Inizialmente era nata per consentire lo scambio di documenti fra università (1990), e a questo stadio era basata su file testuali dobbiamo aspettare il 1993 con l’uscita di Netscape (adesso Firefox :)) per avere un browser grafico.
Nel 1994 nasce il W3c (World Wide Web Consortium) un’ organizzazione no profit con il compito di sviluppare e decidere il futuro del web.
Il World Wide Web è una immensa biblioteca digitale in cui si può spostare tramite collegamenti ipertestuali e l’aiuto di motori di ricerca ed è formata da:
- Web Browser: Firefox, Chrome, Opera: interfaccie grafiche per facilitare la consultazione delle pagine,
- Web Server: computer che offrono le pagine,
- HTML: il linguaggio delle pagine (anche questa)
- HTTP: Hyper Text Transfer Protocol, protocllo di cui parleremo in questo articolo.
Nel Web, visitiamo una pagina HTML: essa è un insieme di oggetti che spaziano da video, a immagini e a scripts. Ognuno di questi oggetti, che deve essere scaricato e caricato dal browser, è accessibile tramite un URL (Uniform Resource Locator).
Ad esempio, quando visiti questa pagina il tuo browser scarica l’ HTML e tutti i riferimenti agli oggetti contenuti come ad esempio il logo:
Esempio di URL: http://blog.informaticalab.com/wp-content/uploads/2013/04/informaticalab400.png
Un URL è formato da diverse parti:
- Http:// = E’ il protocollo utilizzato, http appunto
- blog.informaticalab.com = Il dominio
- /wp-content/uploads/2013/04/informaticalab400.png = Percorso del file all’interno del server.
La normale composizione di un URL è:
protocollo://dominio/path
Ma se dobbiamo, possiamo specificare anche la porta con cui accedere al server:
protocollo://dominio:numeroporta/path
Ad esempio, HTTP utilizza l’ 80 (per convenzione, motivo per cui viene omessa dal browser).
Hyper-Text Transfer Protocol
Questo protocollo è il primo che vediamo sul livello più alto dello stack TCP/IP ovvero sul layer Applicazione. HTTP si basa sul modello Client-Server già visto in precedenza:
- Client: E’ il browser che richiede la pagina
- Server: Invia risposte in base alle richieste del browser
In pratica il compito di HTTP, come ogni protocollo, è quello di stabilire il formato delle richieste e delle risposte contenute nei pacchetti scambiati nel client-server.
Le connessioni HTTP possono essere di due tipi:
Connessioni non persistenti: Un solo oggetto viene trasmesso sulla connessione TCP e ogni coppia richiesta-risposta deve essere trasmessa su connessioni TCP differenti.
Connessioni persistenti: Modalità di default, in questo tipo di connessione più oggetti possono essere trasmessi sulla stessa connessione TCP che rimane attiva per un lasso di tempo prestabilito.

Per chiarire meglio il concetto, ecco i passaggi che avete eseguito per accedere a questa pagina:
- Aperto il browser, vi siete collegati a http://blog.informaticalab.com/reti-protocollo-http/
- Il browser fà “a pezzi” l’ URL ed estrae[fancy_list style=”bullet_list”]
- Il protcollo, che gli dice come deve essere il formato dei messaggi,
- l’ Host: blog.informaticalab.com (si ricava da questo l’ IP usando il DNS che vedremo in seguito – in questo momento comunque non è rilevante)
- La path: /reti-protocollo-http/ [/fancy_list]
Essendo la comunicazione su HTTP, esegue una connessione TCP sulla porta 80 dell’ host.
- Invia la richiesta per il file
- Chiude la connessione
- Apre il file
Quello che succede sul lato server invece è:
- Aspetta una connessione TCP,
- Appena ricevuta, la accetta ed apre un canale
- Riceve il messaggio HTTP contenente il nome del file richiesto
- Invia il file al client
- Chiude o mantiene aperta la connessione TCP asseconda del tipo di connessione vista poco fà.
Il Round Trip Time (RTT) è il tempo richiesto per un messaggio, ad arrivare dal client al server e tornare indietro. E’ ovvio che nelle connessioni persistenti, avremo un RTT per stabilire la connessione, ed uno per ogni file richiesto. Nelle connessioni non persistenti, avremo 2RTT per ogni file richiesto.
Richieste HTTP
Le richieste che fà il nostro browser, sono in formato ASCII. Che vuol dire? Semplice! Che possiamo leggerle! (più avanti vedremo come).
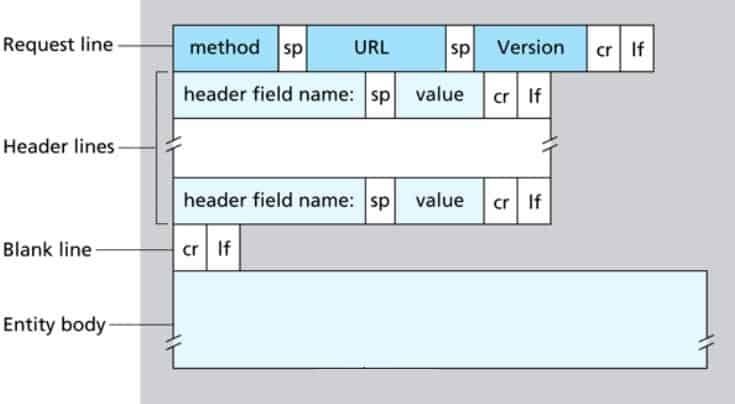
Questo di sopra è il formato generale di una richiesta HTTP:
La prima linea è per la richiesta:
- Method: es: GET, POST;
- URL : file che vogliamo scaricare
- Versione: Versione di HTTP (es: HTTP/1.1)
Dopo questa, cominciano le linee dell’ header (intestazioni) che contengono alcuni dati tipo:
- User-Agent: Il programma client utilizzato per collegarsi
- Accept: Il formato dei contenuti che il client può accettare
- Accept-Charset: Formato dei caratteri che il client può accettare
- Accept-Encoding: Schema di condifica supportato dal client
- Accept-Language: Linguaggio preferito dal client
- Authorization: Le credenziali possedute dal client
- Host: Host a cui si stà collegando e numero della porta
- Date: Data e ora del messaggio
- Upgrade: Protocollo di comunicazione preferito
- Cookie: Comunica il cookie al server (fra poco li vedremo meglio)
- If-Modified-Since: Inviami il documento solo se è più recente della data specificata quì
Un Carriage Return e un Line Feed extra, corrispondono con la fine del messaggio: l’ Entity Body viene usato per le richieste POST.
Quando su un sito ci troviamo davanti ad un Form (es: Google, i forms di login ecc) lo riempiamo e clicchiamo su invio, stiamo inviando dati al Server tramite una richiesta POST appunto e i dati da noi inseriti sono come Corpo Entità.
Per le richieste GET questo campo è vuoto, ma ciò non toglie che non ci permetta di inviare informazioni al server:
http://sito.it/form?nome=Federico&cognome=Ponzi
Continuando a parlare dei Metodi di HTTP 1.1, i principali sono:
- GET: Permette di richiedere una pagina del server. Collegandoci a una pagina, inviamo una richiesta GET al server che ce la manda nel corpo dell’ Entità.
- HEAD: Usato quando il client vuole solo informazioni sul documento: come risposta verranno riempiti solo gli headers del messaggio.
- POST: Per inviare dati al server
- PUT: Per memorizzare un file (contenuto nel corpo dell’ Entità) sul server.
Mancanza di Stato
HTTP è un protocollo State-less (senza stato) ovvero quando un Server serve un Client, subito dopo se ne dimentica. A volte però, è necessario che il server continui a ricordarsi del Client in modo, per esempio, da dargli contenuti personalizzati (vedi per esempio la tua bacheca di Facebook che è diversa da quella di ogni altro utente – o mantenere il “carrello elettronico” nei siti di ecommerce).
La prima cosa che viene in mente è tracciare l’ utente con l’indirizzo ip: strada troppo difficile, gli utenti potrebbero utilizzare computer condivisi o connettersi tramite un router che effettua il NAT (Network Address Translator – vedremo più avanti nel dettaglio).
Per ovviare a questo problema, si sono inventati i Biscotti o meglio conosciuto col nome di Cookies (RFC 2109).
I cookies sono una ottima soluzione per mantenere una sessione e quindi rendere HTTP stateful, ed implementare quindi un contesto che viene mantenuto durante tutta la visita del sito: inoltre la sessione è una cosa logica, ovvero non importa se la connessione è persistente o non persistente.

Una sessione, è caratterizzata da:
- Un inizio e una fine
- Tempo di vita relativamente corto
- Sia server che client possono chiudere la sessione
- La sessione è implicita nello scambio di informazioni di stato.
Il cookie è un ID che si trova in uno dei campi header di HTTP visti poco fà: Quando un utente si collega ad un sito, questo genera un ID che invia all’ utente (tramite gli header) e salva come entry nel suo database.
Quando l’utente si ricollegherà al sito, anche con un ip differente, gli basterà inviare il suo ID tramite HTTP per ritrovarsi nella sessione abbandonata dall’ultima visita.

Il server mantiene quindi tutte le informazioni associate a quell’ ID, e modifica le sue pagine a seconda di esso. Il cookie inviato al client è un identificatore di sessione (SID) e per evitare l’utilizzo da utenti malintenzionati, l’ identificatore è composto da una stringa di numeri.
Set-Cookie: SID=31dg356fg456fddf334
Ogni volta che il client invia una richiesta al server, il browser controlla il file cookie creato in locale per quel sito ed invia il SID contenuto aggiungendolo nella richiesta HTTP.
Cookie: SID=31dg356fg456fddf334
Mentre da locale possiamo eliminare tutti o singolarmente i cookies dalle impostazioni del browser, il server invia un messaggio con Set-Cookie con Max-Age=0
Questo attributo permette di specificare il tempo di vita in secondi del cookie, impostandolo a zero il cookie viene eliminato.
Caching
Presto parleremo anche del Caching del computer, intanto vediamo quello del browser (incredibile il procastinamento: su questo argomento ho pronti 2 articoli su 3 che volevo pubblicare – vabbè).
L’ obbiettivo del Caching è quello di migliorare le prestazioni: un modo semplice consiste nel salvare le pagine richieste spesso per riutilizzarle in seguito senza doverle riscaricare dal server.
Questa tecnica risulta efficiente con pagine che visitiamo spesso (vedi Google).
Il Caching può essere eseguito:
- Dal nostro Browser
- Da un proxy
Caching del Browser
La cache del browser è il primo livello, molto comune e molto usato. Il browser scarica una pagina (es: google.it) e la salva in locale in modo da poterla riproporre in caso di ri-richiesta senza doverla scaricare di nuovo.
Per gestire la cache locale, l’ utente può impostare il numero di giorni dopo i quali i contenuti della cache vanno eliminati, oppure in base all’ ultima modifica del file, stabilire la sua durata di vita (es: la homepage di informaticalab viene aggiornata una volta al dì, quindi nella vostra cache sarà mantenuto per un giorno).
Quelli che si sono cimentati nel web design, ma sicuro a tutti è successo, capita spesso di dover Cancellare la cache perchè il nostro file non è aggiornato.
Caching di un server proxy
I server proxy ci permettono di navigare anonimamente, inviando da parte nostra le richieste al server che contiene le pagine che vogliamo visitare.
Il proxy ha una memoria per mantenere le copie delle pagine visitate e se quando un utente richiede una pagina che non è stata salvata nella memoria (Cache), allora il proxy esegue la richiesta al server che possiede la pagina, la scarica, la salva in cache, e la invia all’ utente.
Gestione della cache
HTTP ci aiuta nel gestire la Cache: esiste infatti nell’ header un campo Expires che indica dopo quanto l’oggetto deve essere considerato Obsoleto, e Last-Modified ci dice la data dell ‘ultima modifica del file – che se è antecedente quella del file salvato in cache, viene riscaricato.
Inoltre, HTTP presenta un meccanismo per verificare se gli oggetti in cache sono aggiornati: questo è il GET Condizionale, che include una riga If-Modified-Since.
Quando viene richiesta una pagina presente in Cache, il browser invia una richiesta HTTP chiedendo se il file è stato modificato (if-modified-since) dalla data in cui l’ha scaricato.
A questo punto il server può rispondere con:
- 304 Not Modified: Il file non è stato modificato, quindi viene presentato all’ utente il file in cache;
- 200 OK: Il file è stato modificato e andrà quindi riscaricato.




Pingback: Netcat: il coltellino svizzero delle reti TCP/IP | InformaticaLab Blog